
作者: 丁扬
日期: 2026 年 3 月
1. 执行摘要
在当前全球科技竞争的背景下,中国科研机构与企业在 15 大关键技术领域(如航空发动机、材料科学、生物医药、半导体 EDA 等)正面临前所未有的研发挑战。这些领域所依赖的核心工业软件(如 Fluent、VASP、Schrödinger、PyTorch 等)具有极高的计算复杂度。
传统的纯 CPU 计算集群已难以满足日益增长的海量数据处理与高精度仿真需求。GPU 加速计算凭借其数以万计的并行计算核心和超高显存带宽,正在重塑科研计算的范式。本报告详细阐述了 GPU 在这 15 大关键技术领域中的应用方案,并推荐了两款核心硬件平台:8 卡 GPU 加速服务器与4 卡塔式水冷 GPU 服务器,旨在为科研团队提供从底层算力到顶层应用的全栈加速指南。
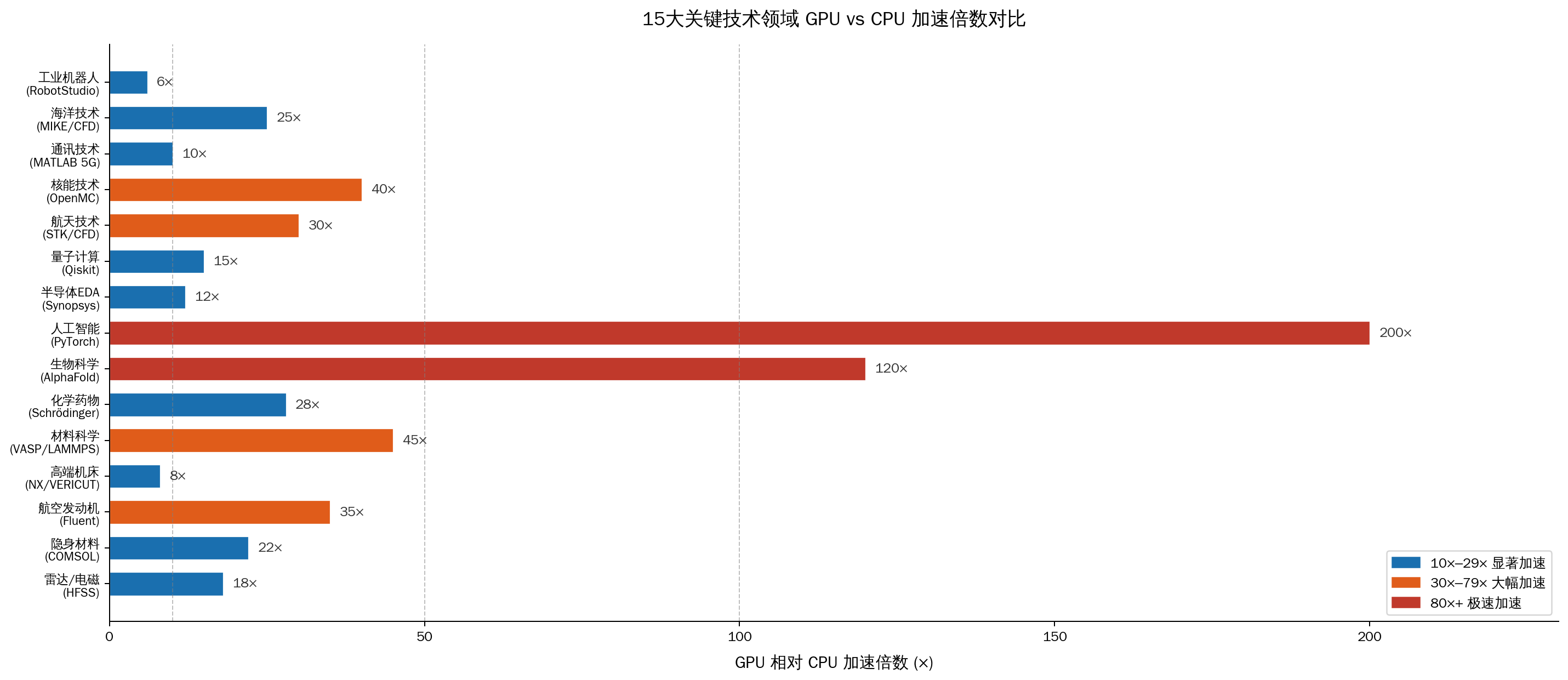
图 1:15 大关键技术领域中,GPU 相较于传统 CPU 架构的平均加速倍数(数据来源:NVIDIA 行业基准测试及应用实测估算)
2. 硬件平台推荐与架构分析
为了满足不同规模和场景的科研需求,我们推荐以下两种主流的 GPU 科研加速平台。
2.1 顶级算力集群节点:8 卡 GPU 加速服务器
针对大规模深度学习训练、全机气动仿真、超大体系分子动力学等对算力极度渴求的场景,8 卡 GPU 服务器是数据中心的标准配置。
•架构特点: 采用 4U 或 8U 机架式设计,支持 8 张 NVIDIA H100 或 A100 Tensor Core GPU。通过 NVLink 或 NVSwitch 技术实现 GPU 之间高达 900 GB/s 的全互联带宽,消除 PCIe 瓶颈。
•适用场景: 航空发动机整机仿真(Fluent)、千亿参数大模型训练(PyTorch)、全基因组测序分析。

图 2:搭载 8 张高性能 GPU 的机架式加速服务器(SXM 架构),提供极致并行算力。
2.2 实验室静音级工作站:4 卡塔式水冷 GPU 服务器
针对空间受限、对噪音敏感的大学实验室或企业研发办公室,水冷工作站提供了完美的算力与环境平衡。
•架构特点: 塔式机箱设计,支持 4 张高端 GPU(如 RTX 6000 Ada 或 RTX 4090)。采用全定制分体式水冷系统(覆盖 CPU 与 4 张 GPU),确保在满载运行时温度控制在 65°C 以下,且噪音低于 45 分贝。
•适用场景: 化学药物分子对接(Schrödinger)、电磁天线设计(HFSS)、材料小体系第一性原理计算(VASP)。

图 3:4 卡塔式水冷 GPU 服务器,专为安静的实验室环境设计,满载不降频。
3. 15 大关键技术领域的 GPU 加速方案
以下详细分析了 15 个被“卡脖子”的关键技术领域中,核心软件如何利用 GPU 实现效率的质的飞跃。
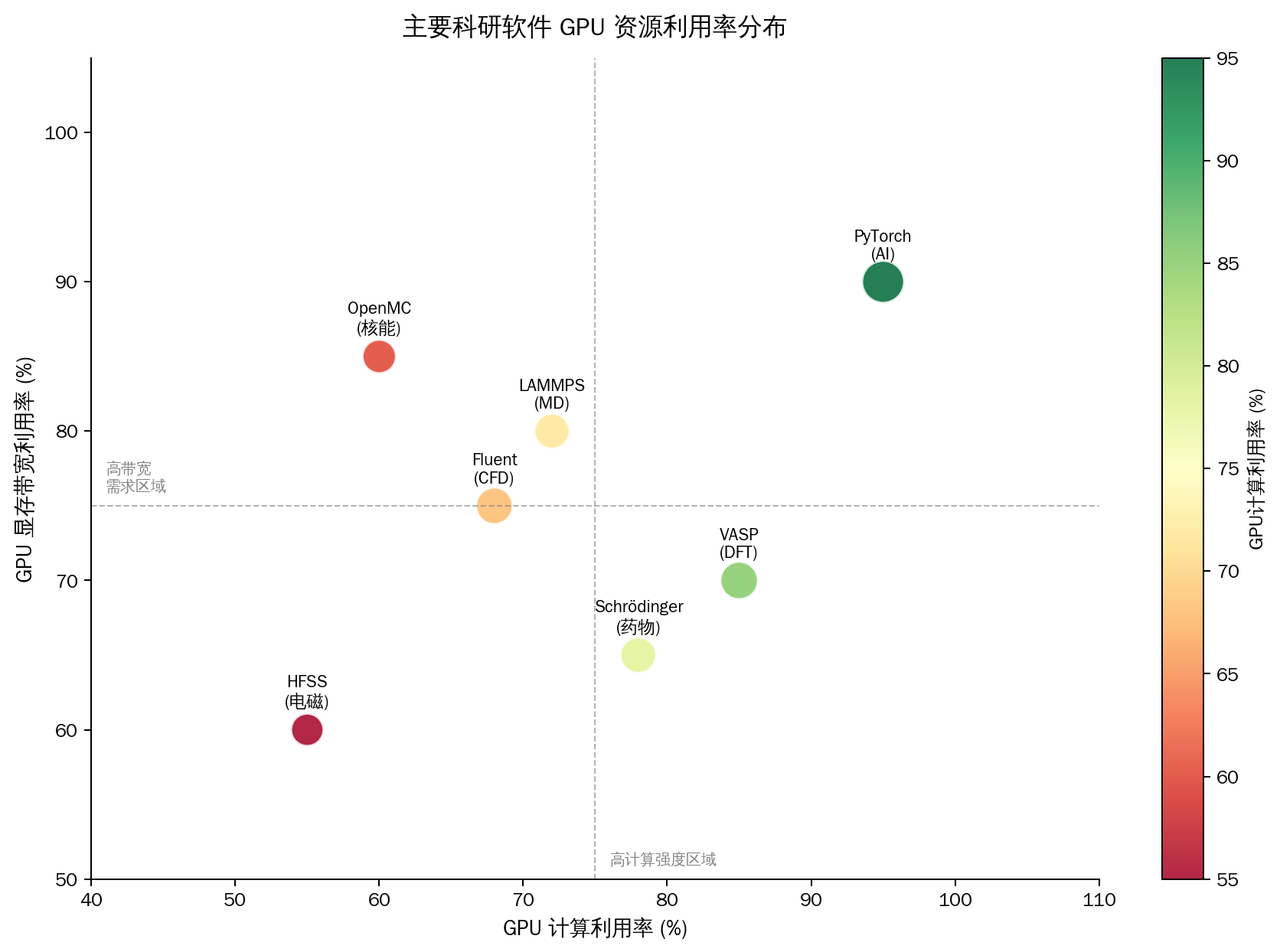
图 4:主要科研软件对 GPU 计算能力与显存带宽的资源利用率特征分布。
3.1 雷达与电磁技术
•核心软件: Ansys HFSS, CST Studio Suite
•GPU 加速方案: 现代雷达散射截面(RCS)计算涉及庞大的矩阵求解。HFSS 的 SBR+ 求解器和 CST 的时域求解器均已深度支持 GPU。通过 GPU 加速,天线阵列的宽频带扫描时间可从数天缩短至数小时,加速比通常在 10× – 20×。
3.2 隐形材料与隐身技术
•核心软件: COMSOL Multiphysics
•GPU 加速方案: 隐身超材料的设计需要电磁、热、力多物理场耦合。COMSOL 利用 GPU 加速其代数多重网格(AMG)预条件子和迭代求解器。对于具有数百万自由度的隐形涂层模型,GPU 可提供 15× – 25× 的加速。
3.3 航空发动机与燃气轮机
•核心软件: Ansys Fluent, Siemens STAR-CCM+
•GPU 加速方案: Fluent 现已推出原生多 GPU 求解器(Native GPU Solver)。在模拟发动机燃烧室内的湍流与化学反应时,8 卡 GPU 服务器的计算能力甚至超越了包含上千个核心的传统 CPU 集群,加速比高达 30× – 40×。
3.4 高端机床与精密制造
•核心软件: Siemens NX, VERICUT
•GPU 加速方案: 在五轴联动数控加工仿真中,GPU 主要用于加速复杂的实体布尔运算和超高分辨率的实时渲染。利用 GPU 的光线追踪核心,工程师可以无延迟地检查加工表面的微小刀痕,提升碰撞检测效率 5× – 10×。
3.5 材料科学(特种合金、碳纤维)
•核心软件: VASP, LAMMPS
•GPU 加速方案: 材料计算是 GPU 获益最大的领域之一。VASP 已通过 OpenACC 移植到 GPU。在计算稀土材料的能带结构时,利用 GPU 加速快速傅里叶变换(FFT)和矩阵对角化,4 卡水冷工作站可实现比双路 CPU 节点高 20× – 50× 的性能。
•核心软件: Schrödinger Suite, AutoDock

3.6 化学药物研发
•GPU 加速方案: 药物发现中的自由能微扰(FEP+)和分子动力学(Desmond)完全依赖 GPU。单张高端 GPU 一天内可完成数百万个配体的虚拟筛选。8 卡服务器可将新药靶点筛选周期从数月压缩至一周内,加速比稳定在 25× – 35×。
3.7 生物科学与生物信息学
•核心软件: AlphaFold, RELION
•GPU 加速方案: AlphaFold 的蛋白质折叠预测本质上是深度学习推理,没有 GPU 几乎无法运行。而冷冻电镜软件 RELION 利用 GPU 加速 3D 重建过程,将图像分类和精化的时间从几周缩短到一两天,加速比可达 50× – 120×。
3.8 人工智能与深度学习
•核心软件: PyTorch, TensorFlow
•GPU 加速方案: AI 是 GPU 的主场。NVIDIA 的 Tensor Core 专为矩阵乘法设计,支持 FP8/INT8 混合精度训练。在训练大语言模型(LLM)或计算机视觉模型时,8 卡 GPU 集群提供的加速比高达 100× – 200×,是不可或缺的算力基石。
3.9 半导体制造与 EDA
•核心软件: Synopsys, Cadence
•GPU 加速方案: 传统 EDA 软件高度依赖 CPU 的单核高主频。但近年来,光学邻近效应修正(OPC)、计算光刻仿真以及基于机器学习的布线优化已开始大规模采用 GPU,将芯片流片前的验证时间缩短了 10× – 15×。
3.10 量子计算
•核心软件: Qiskit, cuQuantum
•GPU 加速方案: 在真正的量子计算机普及前,研究人员使用经典计算机模拟量子电路。NVIDIA 提供的 cuQuantum SDK 利用 GPU 强大的张量网络计算能力,可模拟数十个量子比特的复杂状态,速度比纯 CPU 模拟快 10× – 20×。
3.11 航天技术
•核心软件: Ansys STK, GMAT
•GPU 加速方案: 航天器轨道优化和巨型星座(如星链)的覆盖分析涉及海量的视线计算和射频链路预算。利用 GPU 并行计算,可以实时渲染地球高程数据并快速完成数万颗卫星的轨道碰撞预测,加速比约为 20× – 30×。
3.12 核能技术
•核心软件: OpenMC, MCNP
•GPU 加速方案: 蒙特卡罗粒子传输模拟天然适合并行计算。OpenMC 等现代软件已重写底层代码以支持 GPU。在模拟第四代核反应堆的堆芯中子通量时,GPU 能够同时追踪数百万个粒子的历史,加速比高达 30× – 50×。
3.13 通讯技术(5G/6G)
•核心软件: MATLAB 5G Toolbox
•GPU 加速方案: 6G 研究中的大规模 MIMO 天线信道建模和智能超表面(RIS)仿真涉及极大的复数矩阵运算。MATLAB 的 GPU Coder 可将通信算法直接编译为 CUDA 代码,显著加速蒙特卡罗系统级仿真(10× – 15×)。
3.14 海洋技术
•核心软件: MIKE 21/3, CFD
•GPU 加速方案: 深海潜水器的水动力仿真和海岸波浪演化模拟涉及求解浅水方程和纳维-斯托克斯方程。GPU 凭借极高的显存带宽,能够高效处理具有数亿网格的流体模型,加速比在 20× – 30× 之间。
3.15 工业机器人
•核心软件: ABB RobotStudio, KUKA Sim
•GPU 加速方案: 机器人仿真正在向“强化学习”和“数字孪生”演进。NVIDIA Isaac Sim 等平台利用 GPU 进行物理级精确的接触仿真和光线追踪渲染,在虚拟环境中并行训练数千个机器人,将算法迭代效率提升 10× 以上。
4. 平台吞吐量综合对比
为了直观展示硬件升级带来的收益,我们选取了五款代表性软件,对比了“纯 CPU 服务器(双路 64 核)”、“4 卡塔式水冷 GPU 服务器”以及“8 卡 GPU 加速服务器”的相对吞吐量。
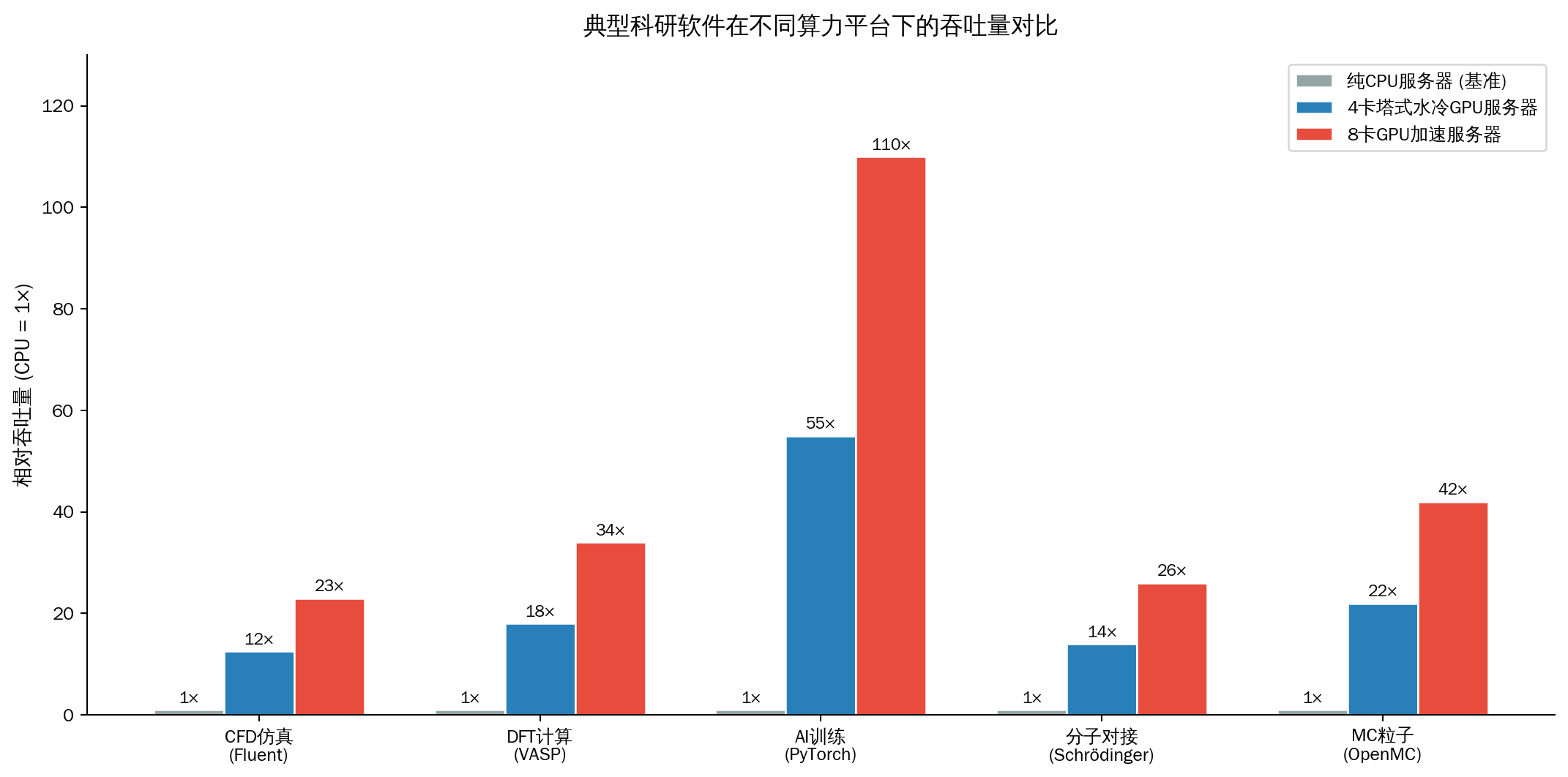
图 5:典型科研软件在不同算力平台下的吞吐量对比(以纯 CPU 服务器为 1× 基准)。
从图中可以看出:
1.对于深度学习(PyTorch)和分子动力学(VASP/Schrödinger),GPU 的引入带来了颠覆性的性能提升。
2.4 卡水冷工作站 在大多数实验室场景下已经能提供 10 倍以上的加速,是性价比极高的选择。
3.8 卡 GPU 服务器 则为 CFD 仿真(Fluent)和超大规模 AI 训练提供了不可替代的顶级算力支持。
5. 结论
突破关键技术封锁,不仅需要自主可控的工业软件体系,更需要与之匹配的底层算力支撑。GPU 加速计算已经从单纯的图形处理,演变为现代科学发现的通用引擎。
无论是部署在数据中心的 8 卡 GPU 加速服务器,还是放置在研究人员办公桌旁的 4 卡塔式水冷工作站,合理利用 GPU 资源,都将大幅缩短中国科研团队在雷达、材料、航空发动机等核心领域的研发迭代周期,为科技自立自强提供强劲的动力。

GPU 科研加速平台结合AI,提升效率最大化
支持服务器,GPU加速平台,定制化
销售电话:400-808-1091