针对大规模深度学习训练、全机气动仿真、超大体系分子动力学等对算力极度渴求的场景,8 卡 GPU 服务器是数据中心的标准配置。
架构特点: 采用 4U 或 8U 机架式设计,支持 8 张 NVIDIA H100 或 A100 Tensor Core GPU。通过 NVLink 或 NVSwitch 技术实现 GPU 之间高达 900 GB/s 的全互联带宽,消除 PCIe 瓶颈。
•适用场景: 航空发动机整机仿真(Fluent)、千亿参数大模型训练(PyTorch)、全基因组测序分析。

搭载 8 张高性能 GPU 的机架式加速服务器(SXM 架构),提供极致并行算力

15 大关键技术领域的 GPU 加速方案。
雷达与电磁技术
•核心软件: Ansys HFSS, CST Studio Suite
•GPU 加速方案: 现代雷达散射截面(RCS)计算涉及庞大的矩阵求解。HFSS 的 SBR+ 求解器和 CST 的时域求解器均已深度支持 GPU。通过 GPU 加速,天线阵列的宽频带扫描时间可从数天缩短至数小时,加速比通常在 10× – 20×
隐形材料与隐身技术
•核心软件: COMSOL Multiphysics
•GPU 加速方案: 隐身超材料的设计需要电磁、热、力多物理场耦合。COMSOL 利用 GPU 加速其代数多重网格(AMG)预条件子和迭代求解器。对于具有数百万自由度的隐形涂层模型,GPU 可提供 15× – 25× 的加速
雷达与电磁技术
隐形材料与隐身技术
航空发动机与燃气轮机
高端机床与精密制造
材料科学(特种合金、碳纤维
化学药物研发
生物科学与生物信息学
人工智能与深度学习
半导体制造与 EDA
量子计算
航天技术
机器人微控制系统
核心控制单元 (Brain) 传感器 (Sensors) 执行器 (Actuators – 电机) 软件与算法 (Software & Algorithms)
运动学与动力学 PID控制算法




机械结构与驱动方案设计,底层控制系统开发(嵌入式控制),视觉/运动感 核心算法运动控制,仿真验证与真机调试





吞吐量综合对比
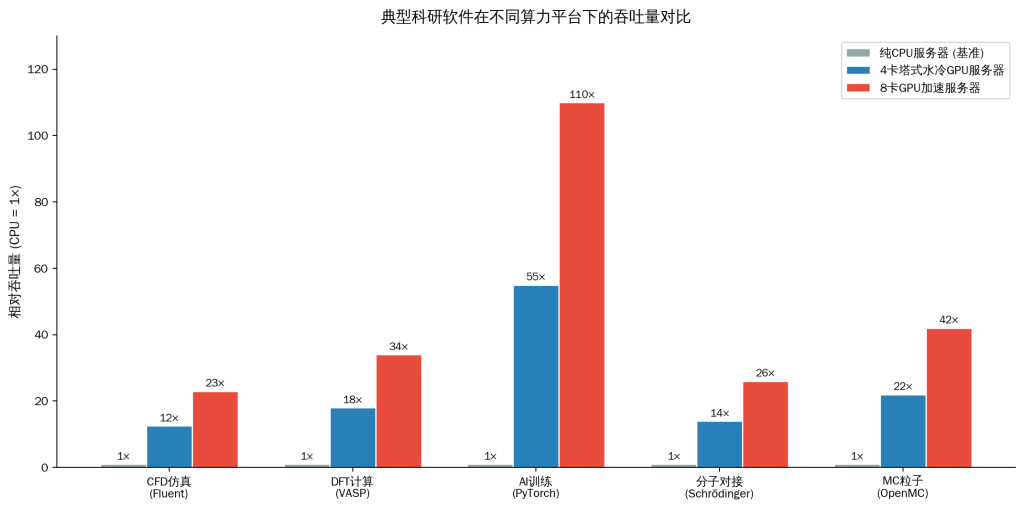
对于深度学习(PyTorch)和分子动力学(VASP/Schrödinger),GPU 的引入带来了颠覆性的性能提升。
2.4 卡水冷工作站 在大多数实验室场景下已经能提供 10 倍以上的加速,是性价比极高的选择。
3.8 卡 GPU 服务器 则为 CFD 仿真(Fluent)和超大规模 AI 训练提供了不可替代的顶级算力支持。
核心软件: OpenMC, MCNP
•GPU 加速方案: 蒙特卡罗粒子传输模拟天然适合并行计算。OpenMC 等现代软件已重写底层代码以支持 GPU。在模拟第四代核反应堆的堆芯中子通量时,GPU 能够同时追踪数百万个粒子的历史,加速比高达 30× – 50×。
雷达与电磁技术
•核心软件: Ansys HFSS, CST Studio Suite
•GPU 加速方案: 现代雷达散射截面(RCS)计算涉及庞大的矩阵求解。HFSS 的 SBR+ 求解器和 CST 的时域求解器均已深度支持 GPU。通过 GPU 加速,天线阵列的宽频带扫描时间可从数天缩短至数小时,加速比通常在 10× – 20×。。
材料科学(特种合金、碳纤维)
•核心软件: VASP, LAMMPS
•GPU 加速方案: 材料计算是 GPU 获益最大的领域之一。VASP 已通过 OpenACC 移植到 GPU。在计算稀土材料的能带结构时,利用 GPU 加速快速傅里叶变换(FFT)和矩阵对角化,4 卡水冷工作站可实现比双路 CPU 节点高 20× – 50× 的性能
顶级算力集群节点:8 卡 GPU 加速服务器。
- 支持 8 张 NVIDIA H100 或 A100 Tensor Core GPU
- 过 NVLink 或 NVSwitch 技术实现 GPU 之间高达 900 GB/s 的全互联带宽
- 将芯片流片前的验证时间极致缩短

定制化服务热线:400-808-1091